One of the key challenges we need to solve is to provide in-depth monitoring capability for our next generation platform. Currently we use cron to schedule some of recurring jobs. While cron is easily to setup, it provides no visibility into if and when the job was executed, the status of the job execution (success, fail, or still ongoing).
In this blog, we will show how to configure Mule Studio and Quartz connector so jobs can be monitored by Quartz manager.
From Terracotta's web site,
"Quartz Manager provides real-time monitoring and management for Quartz Scheduler. Use its rich graphical user interface to:
- Gain immediate visibility into job schedules, status and activity
- Readily add or modify scheduling information
- Manage multiple instances of Quartz Scheduler through a single interface
- Simplify ongoing management of job scheduling and execution
Quartz Manager is an enterprise-grade addition to Quartz Scheduler that comes with a commercial license and support."
We really like the facts that Quartz monitoring is JMX based and Quartz manager works with existing Quartz schedule w/o any configuration changes, other than enabling JMX support.Here are the necessary steps to integrate Quartz end point with Quartz Manager.
Download and Install Quartz Manager
Follow the link to download and install Quartz Manager.
Enable JMX for Quartz Connector inside Mule Studio
Next we must enable JMX for both Quartz Connector and when we run the Mule flow.
Enable JMX for Quartz Connector
Enabling JMX for Quartz connector is accomplished through setting the following "quartz:factory-property" entries,
<quartz:factory-property key="org.quartz.scheduler.jmx.export"
value="true" />
<quartz:factory-property key="org.quartz.scheduler.jmx.objectName"
value="quartz:type=QuartzScheduler,name=JmxScheduler,instanceId=NONE_CLUSTERED" />
Replace org.quartz.scheduler.jmx.objectName's name and instanceId with one's own appropriate values.
Enable JMX Remoting when Running Mule Flow
Now we need to enable JMX remoting when running Mule Flow. Go to eclipse->Run->Run Configuration. Find the run configuration for the existing flow under "Mule Application". Add the following entries to VM arguments,
-XX:PermSize=128M -XX:MaxPermSize=256M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.ssl=false
Upgrade Quartz JAR File in Mule Studio
Next we need to upgrade the quartz-all.jar file shipped with Mule Enterprise Studio. Currently Mule ships quartz-all-1.6.6.jar, which is very old and won't work with Quartz manager. We can't use the most recently release of Quartz as the most recent version breaks the backward compatibility and Mule won't support it. Download quartz-all-1.8.6.jar from Terrocatta's web site.
Go to MuleStudio installation directory and replace quartz-all-1.6.6.jar with quartz-all-1.8.6.jar.
We also need to fix the built-in Mule runtime libraries reference to quartz-all-1.6.6.jar with quartz-all-1.8.6.jar. Mule runtime dependency is defined in a MANIFEST.MF file under your Mule studio installation directory. Locate this file, replace quartz-all-1.6.6.jar with quartz-all-1.8.6.jar.
Start Mule Flow and Quartz Manager
Now we can start Mule Flow and Quartz Manager.
When Quartz Manager first starts up, it asks for JMX host and port number,

Enter the correct host name and port number.
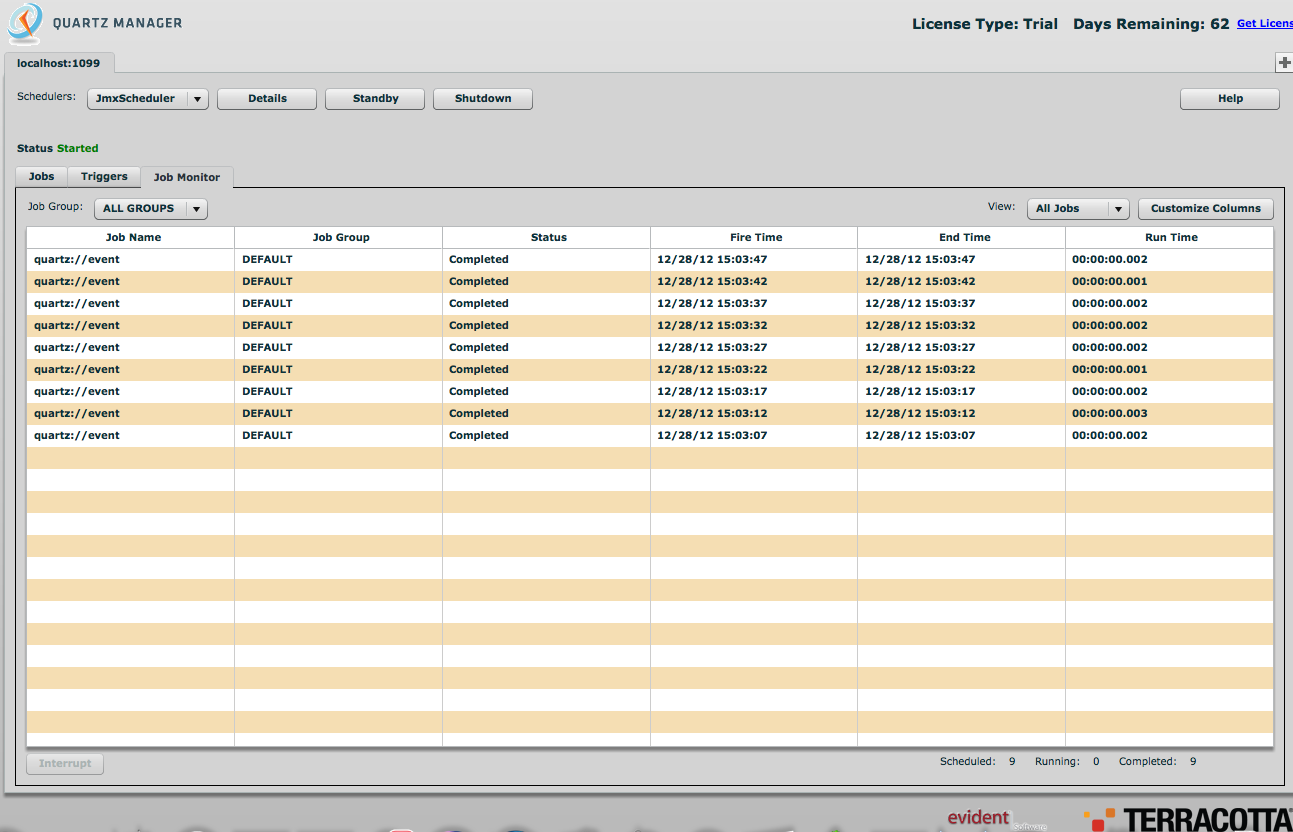
After successfully connecting to the remote Quartz scheduler, Quartz manager display the following job details page,

Click on "Triggers" to show trigger details.

Click on "Job Monitor" to see the detailed status for each executed job.